思享家|ThousandEyes网络报告 解读CrowdStrike更新事件
浏览量:1064 上传更新:2024-08-16

思科联天下 思科渠道微情报

Mike Hicks
Principal Solutions Analyst
思享家是一个介绍如何利用思科先进技术解决客户难题的栏目。每期聚焦一个技术热点或应用场景,邀请资深思科技术专家深入浅出地介绍,为读者提供实用性强的建议。
ThousandEyes互联网报告团队解析了近期因CrowdStrike更新而导致的一系列全球IT中断、一次时间相近但独立的Azure中断,以及其他近期的中断事件。
您可以点击文末阅读原文阅读完整的分析报告。
7月18日,我们遇到了两个看似具有共同点,但实际上是独立存在的中断事件。
首先,由于Microsoft Azure美国区域的问题,一些公司在美国部分地区的Azure服务(依赖于Azure Storage)出现了问题。
接着,网络安全技术公司CrowdStrike在其常规操作中进行的内容配置更新导致了一系列全球性的IT中断。这些中断使得航空公司和机场、银行、运输运营商、餐厅、超市等多个行业的大量Windows机器显示蓝屏死机(BSOD,Blue Screen of Death)。
由于Azure和CrowdStrike事件发生在同一时间段,并且都涉及到Microsoft产品,一些人最初认为这些中断是相关的;然而,事实证明它们是独立且无关的事件。
CrowdStrike事件
中断初步责任被认定归于微软
在这次大规模中断事件中,最初的责任被认为是微软的,因为受影响的系统和设备都是基于微软的,而且当天早些时候,微软在其美国中部地区经历了一次中断。
此次中断影响了使用Windows客户端或Windows服务器的系统和服务,包括可能在Windows系统上运行的服务,如Active Directory(AD)。
然而,随着IT管理员的分析逐渐通过互联网论坛和社交媒体传播,一个不同的共同因素浮现出来:CrowdStrike,这是一种用于保护Windows端点免受攻击的托管检测和响应(MDR)服务。
CrowdStrike发布了他们的第一份公开声明,帮助初步澄清了问题原因。在这份初步声明之后,CrowdStrike发布了针对IT管理员的操作指南和解决方法,并发布了一份技术事件报告,将事件归因于一个配置文件的问题,该文件“触发了一个逻辑错误,导致系统崩溃和蓝屏(BSOD)。”
在大规模中断期间,第一个问题通常不是“是否有中断?”而是“是什么导致了这个问题?”紧随其后的问题是“谁负责解决这个问题?”
回答这些问题的速度取决于可用信息的水平、完整性和准确性。在缺乏完整信息的情况下长时间操作,可能会导致基于某种看法(如“服务无法访问”)的假设。
ThousandEyes以两种方式
观察到了CrowdStrike事件的影响
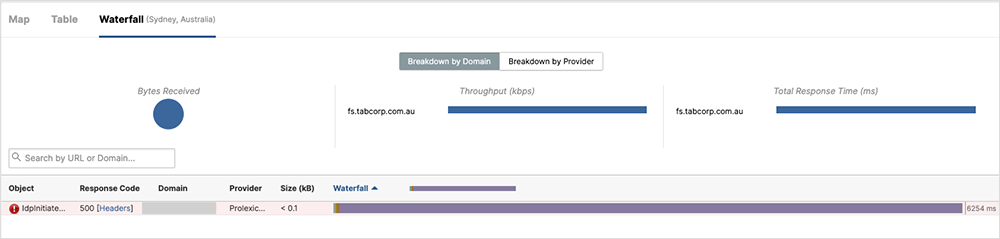
◎ 流量丢失:当前端应用以及托管在Microsoft Windows服务器上的服务流量丢失的情况下。由于服务器无法正常工作,它们不能正常的接收和响应入向流量,将会导致服务丢失(见下图1)
△ Figure 1. Path connectivity to Windows host not located on the Microsoft network
◎ 服务器超时以及应用和服务的HTTP 500错误,并且托管在CDN上的服务或者其他基础设施不能访问运行在微软windows上的后端服务。
△ Figure 2. Web service responding with an HTTP 500 Internal Server error when trying to retrieve content from backend resources running on Windows hosts
根据这些信息,IT用户可以通过结合ThousandEyes的数据及视图来缩小故障域并识别问题的根源。这一过程通常从网络开始,因为网络是最大的域,因此流量会在这里花费最多的时间。
因此,不仅是排查故障的最佳起点,而且一旦确定网络没有问题,就能排除大量潜在原因。
在本例中,网络没有显示出重大问题或性能下降,跨越了多个地区和托管位置,表明网络本身并不是问题。然而,之前观察到的两种情况都与服务器问题高度相关,例如服务器变得无响应或服务器上的应用代码不再正常工作。
这一事件突显了数字体验中的复杂性,远比人们意识到的要多得多。只需要一个组件,甚至仅仅是一个功能的失效或性能下降,就足以使整个服务交付链停止运作。
当发生中断时,重要的是高效地确定问题的来源,而这一过程中的关键步骤是识别问题不在于哪里。确保数字体验不仅仅涉及网络,还需要考虑从设备到应用的所有因素。
进一步加剧混乱的是,Microsoft在其一个美国Azure区域也经历了问题,巧合的是,该区域还托管了一些客户的Windows服务器。这种巧合进一步增加了事件的复杂性,使得确定问题的根源变得更加困难。
在CrowdStrike事件影响显现的几小时前,微软经历了一次无关的中断,这次中断影响了访问各种Azure服务和配置为单一区域服务的客户账户,特别是位于美国中部区域。
该中断发生在2024年7月18日晚上9:56(UTC)到7月19日中午12:15(UTC)之间。两起事件的时间接近可能引起了一些混淆,并导致较大的全球IT中断被错误地归咎于微软。
尽管微软系统在CrowdStrike事件期间受到了影响,但这与Azure中断完全无关。
根据状态更新,一些客户遇到了多个Azure服务的问题,包括服务管理操作失败和服务的连接性或可用性问题。
到达美国中部区域的网络路径似乎不受影响。但是到达美国中部区域的连通性受到了影响,在受影响的区域观察到了入向的转发丢失。此问题主要影响在美国中部区域配置为在此地区单区域可用性的用户会遇到可用性问题,而在美国中部区域拥有多个读区域和单个写入区域的用户可能会遇到性能下降。
受影响的用户包括Confluent、Elastic Cloud 和Microsoft 365。
△ Figure 3. Network path to the Central US region is unaffected, while connectivity into the Central US region displays forwarding loss entering the affected region.
微软的状态更新还指出,确认了一个配置更改是影响后端服务连接性的根本原因。
特别是对于存储集群和计算集群。然后引发了一些自修复服务被反复重启。
由于存储集群影响了部分的Azure SQL数据库访问,微软启动了修复流程,包括为客户数据库提供跨地区容灾,协助恢复故障。
在这种数字化体验受到影响的情况下,理解哪些服务之间有关联与否至关重要,可以避免浪费时间和资源。在这个场景下,理解哪些服务和功能受到了影响,哪些正在被提供服务,哪些地区正在受到影响。这些信息会为缓解故障以及未来优化起到了至关重要的性作用。